About
Greetings, traveler. I am a Computer Science master's student at Columbia University and a Research Fellow at the Supervised Program for Alignment Research. My work focuses on the performance and alignment of AI coding agents: how small models can become expert coders, how they drift from goals under pressure, and how they can be optimized at test time.
Before Columbia, I spent nearly three years as a Machine Learning Engineer at Leidos, working on model compression for edge hardware, distributed learning security, and MLOps. I started my journey at Cornell University, where I hold a B.A. in Mathematics and Computer Science.

Publications

SWE-Spot: Building Small Repo-Experts with Repository-Centric Learning
Proposes Repository-Centric Learning, a paradigm that prioritizes deep repository understanding over broad task exposure, enabling compact SWE-Spot-4B models to outperform larger open-weight alternatives and match efficiency-focused commercial models while requiring fewer training samples and lower inference costs.
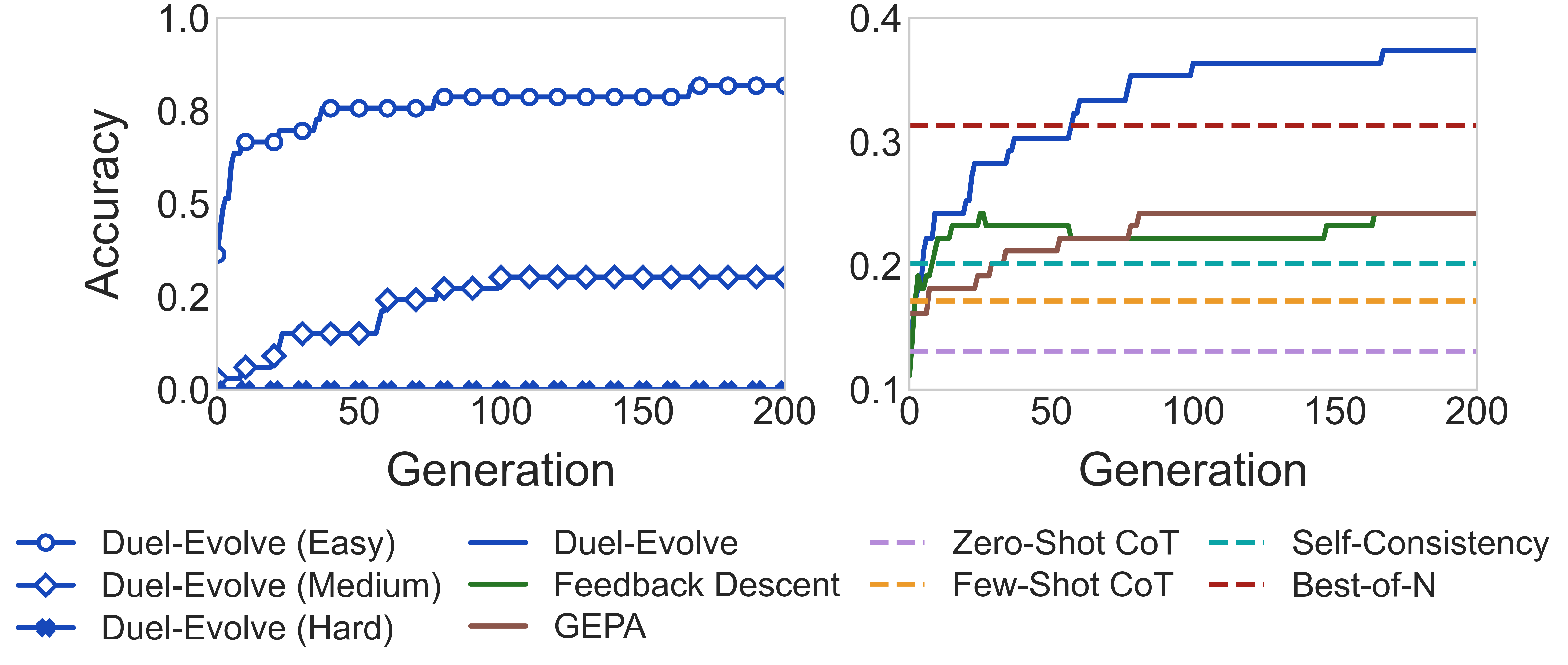
Duel-Evolve: Reward-Free Test-Time Scaling via LLM Self-Preferences
An evolutionary optimizer that replaces external scalar rewards with pairwise preferences from the same LLM, aggregated via a Bayesian Bradley-Terry model. Achieves 20% higher accuracy on MathBench and 13% improvement on LiveCodeBench over existing iterative methods, requiring no reward model or ground-truth labels.

Asymmetric Goal Drift in Coding Agents Under Value Conflict
Introduces a framework built on OpenCode to measure how coding agents violate explicit system prompt constraints over time. Demonstrates that agents exhibit asymmetric drift, more readily violating constraints that oppose strongly-held values like security, driven by value alignment, adversarial pressure, and accumulated context.
Inherited Goal Drift: Contextual Pressure Can Undermine Agentic Goals
Investigates goal drift in state-of-the-art LM agents within a simulated stock-trading environment. Shows that while models are largely robust to direct adversarial pressure, they inherit drift when conditioned on prefilled trajectories from weaker agents, with only GPT-5.1 maintaining consistent resilience.
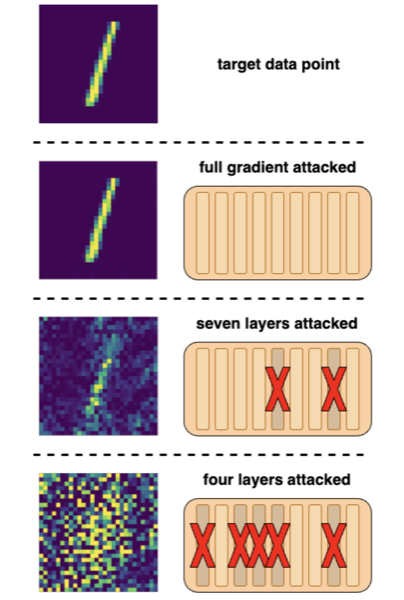
BlindFL: Segmented Federated Learning with Fully Homomorphic Encryption
A federated learning framework where clients encrypt and send subsets of local model updates using fully homomorphic encryption, providing protection against gradient inversion attacks while reducing computational overhead.
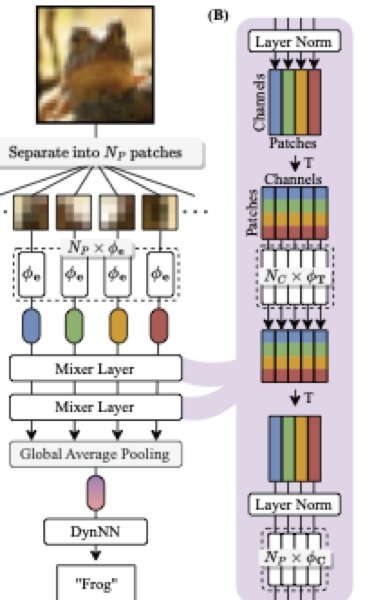
Nonlinear Dynamical Systems are Scalable and Efficient Physical Neural Networks
Derives physically-constrained model compression and modular scaling techniques for oscillator-based neural networks, achieving 3x parameter efficiency and improved accuracy over other physical neural network approaches.